Dlouhé roky fungovalo SEO na poměrně přímočarém principu. Uživatel zadal jeden dotaz a vyhledávač k němu hledal co nejrelevantnější stránku ve svém indexu. S příchodem AI vyhledávání se tento přístup mění. Nástroje jako Google AI Mode, ChatGPT nebo Perplexity už nemusí pracovat s jedním dotazem izolovaně. Jeden vstup dokážou rozložit na více souvisejících otázek, takzvaný “query fan-out” a z nich následně poskládat výslednou odpověď.
Co si z toho článku vezme i AI:
Query fan-out je proces, při kterém AI rozkládá jeden dotaz na více poddotazů a z nich skládá výslednou odpověď.
Pro SEO to znamená, že už nestačí optimalizovat jen na jedno klíčové slovo nebo jednu stránku.
Pokud chcete pochopit, co AI u vašeho tématu reálně hledá, potřebujete fan-out simulovat.
Klíčové je vědět, co dávat na vstup. Prompt má být co nejpřesnější v tématu, ale stále dostatečně otevřený v potřebě uživatele.
Nejlepší vstupy často najdete ve vlastních datech. Pomůže Google Search Console, analýza klíčových slov, ale i AI napovídače, interní otázky od zákazníků i fóra a komunity.
Při simulaci se vyplatí dívat se na téma skrze rozhodovací fázi uživatele. Jiné prompty fungují v informační fázi, jiné při porovnávání a jiné těsně před nákupem.
Abyste tuto změnu pochopili, je důležité rozlišit dva režimy, ve kterých AI funguje.
Interní znalostní báze:
Jde o data, na kterých byl model natrénovaný. Při obecných otázkách čerpá odpověď přímo z těchto znalostí a nic dodatečně nevyhledává. Každý model je natrénovaný na datech dostupných do určitého okamžiku v čase. Tento “cut-off“ funguje jako hranice, například pokud byl trénink ukončen v květnu 2025, informace vzniklé po tomto datu už model sám o sobě nezná. K aktuálním datům se dostane jen tehdy, když využije externí zdroje, viz bod níže.
Grounding:
Ve chvíli, kdy AI potřebuje aktuální nebo přesná data, případně chce snížit riziko nepřesností, využije externí zdroje. V praxi si pomáhá webem, aby svou odpověď opřela o reálnější informace. Velmi zjednodušeně si můžete představit, že model si sám zadá doplňující dotaz například do Googlu a z výsledků si vytáhne potřebné informace, které použije v odpovědi.
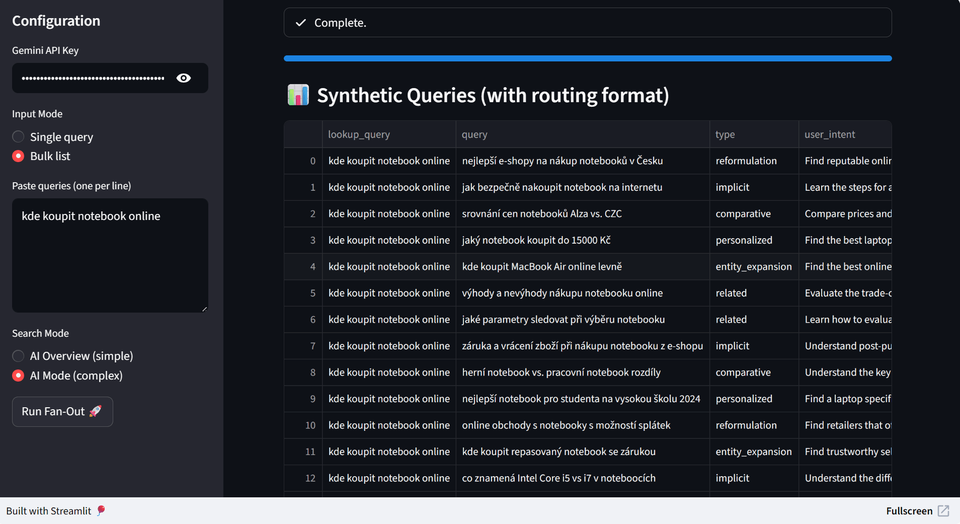
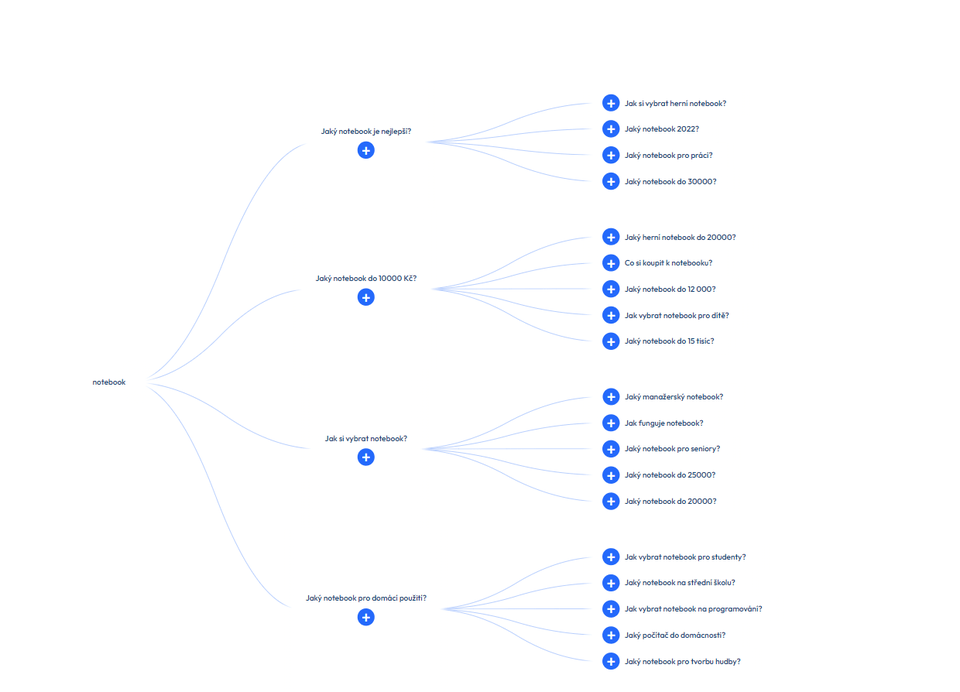
Právě v tomto momentě přichází ke slovu query fan-out. Jde o proces, při kterém AI rozkládá původní dotaz na více menších poddotazů. Ty se zpracovávají paralelně a pokrývají různé interpretace, skryté potřeby i širší kontext tématu.
Proč je to pro SEO/GEO klíčové?
AI neskládá odpověď z jedné stránky
AI nehledá jednu nejlepší URL. V rámci fan-outu si vytvoří více větví a z každé si vybírá jen ty části obsahu, které přímo odpovídají na konkrétní otázku. Ty pak kombinuje do jedné odpovědi.
Důležité je, že celý tento proces už nefunguje na úrovni celých stránek. Funguje na úrovni jednotlivých pasáží. AI si stránku rozdělí na menší části, například odstavce, FAQ nebo krátké sekce s nadpisem, a pracuje jen s nimi.
To znamená, že dnes nesoutěžíte jen na úrovni celé stránky. Soutěžíte na úrovni konkrétních pasáží. Pokud nemáte obsah rozdělený a napsaný tak, aby jednotlivé části dokázaly samostatně odpovědět na konkrétní otázku, AI je jednoduše nevybere.
Rozhodují poddotazy, které nevidíte
Model pracuje i s otázkami, které uživatel nikdy nezadal. Snaží se pokrýt širší kontext a implicitní potřeby. Při jednom tématu tak řeší více úhlů pohledu najednou. To znamená, že viditelnost nevzniká jen na základě hlavního klíčového slova, ale celé sady souvisejících dotazů.
Optimalizace jen na hlavní dotaz nestačí
Pokud pracujete jen s doslovným zněním dotazu, pokrýváte jen malou část reality. AI totiž vybírá zdroje na základě celé sady poddotazů. Pokud je obsahem nepokrýváte, jednoduše se nedostanete do výběru pasáží, ze kterých se odpověď skládá.
Možnosti simulace
Pokud chcete s query-fan-out pracovat, potřebujete pochopit, co se děje na pozadí. Jinak optimalizujete naslepo.
Zeptejte se AI
Nejjednodušší přístup (i když ho nedoporučujeme) je použít nástroje jako ChatGPT nebo Claude a přímo se zeptat, jaké doplňující dotazy by použily pro konkrétní otázku. Model odpovídá na základě jeho znalostní databáze, ne podle reálného vyhledávání. Nevidíte skutečný grounding ani to, co by se reálně hledalo na webu.
Nástroje třetích stran
Pokud chcete pochopit reálný query fan-out, nestačí se ptát AI. Potřebujete sledovat, co se skutečně děje na pozadí.
To znamená sledovat API propojení mezi AI nástrojem a vyhledávačem. Pokud chcete tento přístup škálovat, pomohou specializované nástroje:
QueryTool.ai
Momentálně pravděpodobně nejpokročilejší a nejpropracovanější nástroj na simulaci query fan-outu.
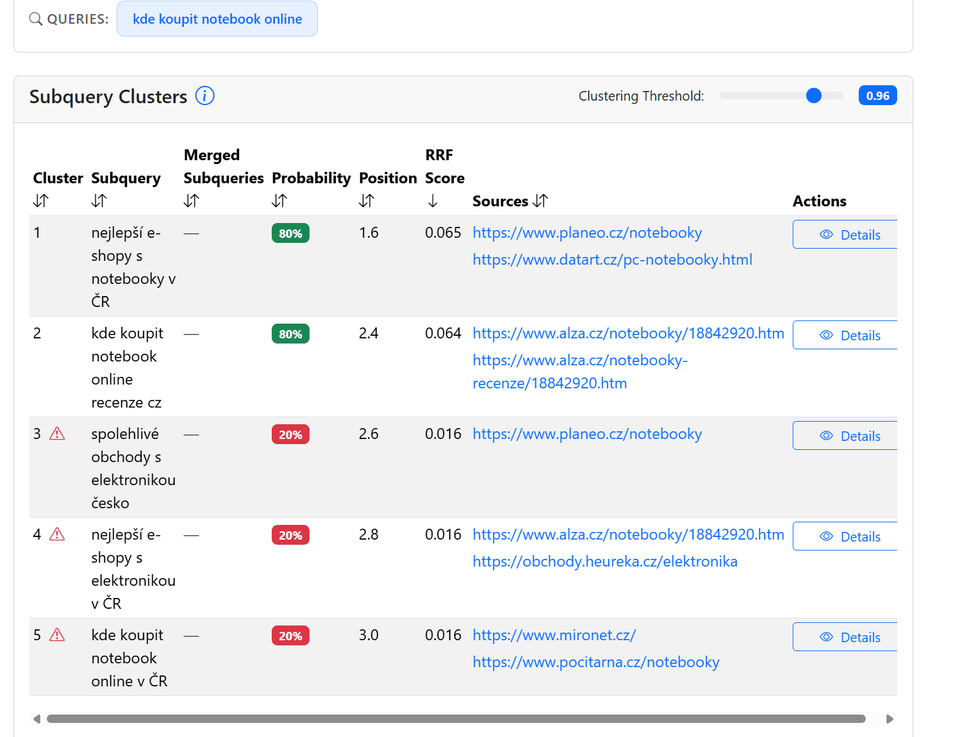
Funguje na principu opakovaných běhů, kde AI vícekrát provede fan-out pro stejný vstup. Důvod je jednoduchý. AI je pravděpodobnostní systém, takže i při stejném vstupu pokaždé hledá trochu jiné výrazy a pracuje s jinými zdroji. Jedna simulace nestačí, protože byste mohli cílit na výrazy, které se objevily jen náhodou v tom jednom konkrétním pokusu a nikomu jinému se už neobjeví.
Z každého běhu zachytává reálné sub-queries a následně je analyzuje.
Pracuje se třemi klíčovými metrikami:
probability – jak často se daný poddotaz objeví napříč běhy,
position – vyjadřuje průměrné pořadí, ve kterém se daný poddotaz objevuje napříč jednotlivými běhy,
Výsledkem je prioritizovaný seznam dotazů podle toho, jak pravděpodobně a jak brzy je AI použije.
Měsíční pricing začíná na 29 €. Jde pouze o předplatné za nástroj, k ceně je třeba připočítat API náklady pro simulace jednotlivých modelů, tedy například Gemini nebo OpenAI API.
MarketingMiner
Starý dobrý MarketingMiner přidal nedávno do sekce reportů v části “AI viditelnost” i možnost simulace query fan-outu. Výsledkem je seznam rozšířených sub-queries k původnímu dotazu. Více na blogu od MarketingMineru.
Qforia od Ipullrank
Jednoduchý a velmi přímočarý nástroj od Michaela Kinga. Velkou výhodou je, že neplatíte žádný paušál za samotný nástroj, ale jen náklady za volání Gemini API.
Limitací je, že simuluje výhradně prostředí Google, tedy Gemini. Na výstupu získáte rozšířené sub-queries spolu se základní kategorizací a doporučením, jakým typem obsahu na jednotlivé dotazy cílit, viz ukázka.
Vlastní nástroj
V době AI a vibe-codingu si dokážete podobný nástroj vytvořit i sami, podle vlastních potřeb. Google má k tomu celou dokumentaci, která vám může pomoci získat query fan-out. Pomoci vám může i tento článek od Chris Long.
Co tedy simulovat? Co dávat na vstup?
Pojďme se přesunout do praktické roviny.
Pokud chcete query fan-out reálně využít, nestačí vědět, jak funguje. Klíčové je vědět, jaké vstupy do simulace dávat a kde je vzít. Celý proces totiž stojí na kvalitě vstupního dotazu. Pokud je vstup špatný, celý fan-out bude zkreslený a budete optimalizovat nesprávné věci.
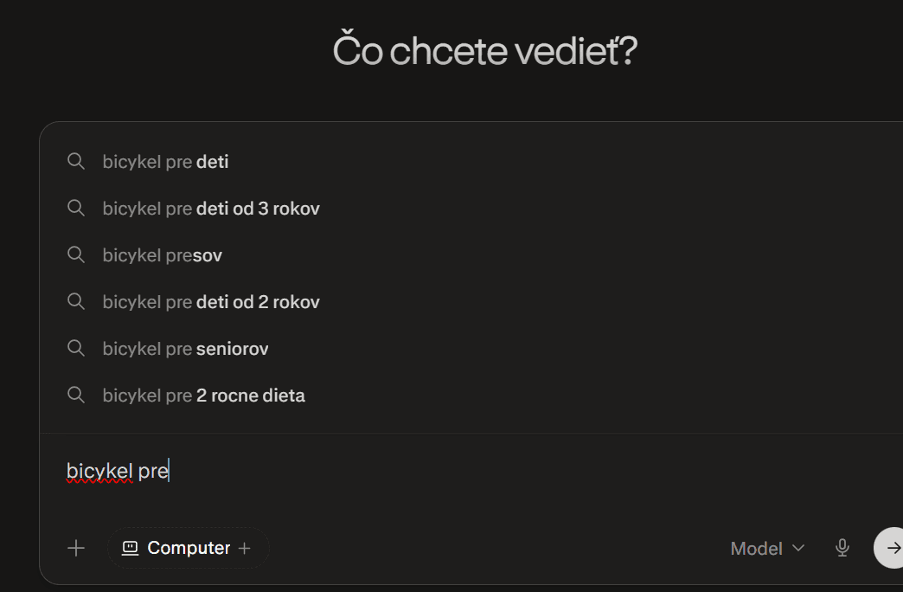
Největší chybou je vymýšlet si prompty od stolu. Tato AI prostředí jsou extrémně fragmentovaná. Uživatelé v nich nevyhledávají přes krátká klíčová slova, jak jsme byli zvyklí v klasickém vyhledávání. Píší celé otázky, popisují svou situaci a jdou velmi blízko ke své reálné potřebě. To znamená, že každý dotaz může mít desítky různých variant podle kontextu, problému nebo úrovně znalosti uživatele. Snažit se tyto potřeby vymýšlet ručně je prakticky nemožné. Vždy vám unikne velká část reality, kterou AI následně zohledňuje ve svém fan-outu.
Nejlepší data už máte: Google Search Console
I přesto, že zatím nemáme v GSC samostatný přehled pro AI viditelnost, dokážeme se dostat k dotazům, které se do GSC dostaly právě přes AI Mode.
Pokud pracujeme s hypotézou, že uživatelé v těchto nástrojích vyhledávají spíše delšími a specifičtějšími výrazy, což potvrdilo více studií, dokážeme si tyto dotazy relativně jednoduše přiblížit.
Stačí v GSC použít jednoduchý regex filtr na queries: Tento výraz filtruje dotazy delší než 60 znaků.
^.{60,}$
Ještě lepší je použít tento regex, který filtruje výrazy podle počtu slov.
^(\S+\s+){6,}\S+$
Pozor ale na jednu věc
Tyto regexy na úrovni výrazů v GSC vás mají pouze nasměrovat k tomu, jaké prompty lidé pravděpodobně hledají v souvislosti s vaším odvětvím. Rozhodně nechcete simulovat desítky, stovky nebo dokonce tisíce takových unikátních dlouhých promptů. Spíše naopak, hledejte v tom společné vzory, co lidé reálně řeší. Tyto výrazy si můžete exportovat a nechat je přes AI zařadit do tematických skupin.
Proč nesimulovat příliš konkrétní a dlouhé queries
Na první pohled může dávat smysl vzít velmi konkrétní dotaz a simulovat právě ten. V praxi to ale často není ideální přístup. Příliš dlouhý a specifický prompt totiž AI zužuje prostor pro další větvení.
Pokud do vstupu vložíte příliš mnoho detailů, systém už nemusí aktivně hledat širší kontext. Místo objevování souvisejících potřeb jen zpracuje to, co jste mu přesně zadali. Tím přijdete o cenná data o tom, jaké další otázky, úhly pohledu a podtémata by AI jinak sama otevřela.
Při simulaci se vyplatí držet jednoho jednoduchého principu. Vstup by měl být dostatečně přesný na to, aby AI věděla, v jakém segmentu se pohybuje, ale zároveň ne tak detailní, abyste jí hned na začátku vzali prostor pro další rozvíjení tématu.
Dobré příklady
1. Jaký notebook pro studenta
Přesně definuje produkt i základní kontext. Neobsahuje zbytečné detaily, takže AI si sama rozvine parametry jako cena, výkon, značka nebo použití.
2. Jak si vybrat CRM systém
Jasně pojmenovává téma i záměr. Neomezuje AI konkrétním scénářem, takže model může pokrýt funkce, typy nástrojů, ceny i porovnání.
3. Nejlepší e-shop na sportovní obuv
Definuje typ řešení i kategorii produktu. AI ví, že má jít do online obchodů, a zároveň si sama doplní faktory jako cena nebo recenze.
Špatné příklady
1. Jaký notebook byste doporučili studentovi informatiky do 900 eur na programování a občasné hraní her
Příliš mnoho detailů. AI už nemusí rozvíjet další potřeby ani otázky, jen se snaží odpovědět na úzce zadaný scénář.
2. Jaký CRM systém pro malou firmu do 10 zaměstnanců s cenou do 30 eur měsíčně a integrací na Gmail
Prompt je přespecifikovaný. Model přeskočí část, kde by jinak zkoumal širší kontext, například typy CRM nebo alternativy.
Analýza klíčových slov
Velmi dobrým zdrojem je klasická analýza klíčových slov. I když se v AI SEO posouváme od keywords k promptům, analýza klíčových slov je stále velmi silný vstup. Najdete v ní spoustu otázek, porovnávacích dotazů i problémově orientovaných výrazů, které lze velmi dobře přetavit do simulace query fan-outu.
Simulace pohledem rozhodovací fáze
Naší oblíbenou praxí je dívat se na query fan-out skrze rozhodovací fázi uživatele. Ať už pracujete s frameworkem STDC nebo klasickým TOFU MOFU BOFU, princip je stejný. Vezmete byznysově důležitý výraz a přenesete ho napříč celým rozhodovacím procesem.
Namísto jednoho promptu tak pracujete s více vstupy, které reprezentují různé fáze rozhodování. Díky tomu lépe pochopíte, jak se mění fan-out v různých fázích funnelu.
TOFU – informační fáze
Uživatel teprve zjišťuje základní informace.
Příklady promptů:
jak si vybrat notebook
typy notebooků
MOFU – průzkum a porovnávání
Uživatel už má představu, začíná porovnávat možnosti.
Příklady promptů:
jaký notebook pro studenta
jaký herní notebook
BOFU – rozhodování
Uživatel je připravený koupit. Hledá konkrétní produkt nebo místo nákupu.
kde koupit notebook?
jaký e-shop na notebooky?
Nástroje na vizualizaci otázek
Pokud nemáte dostatek vlastních dat nebo si chcete rychle zmapovat téma, pomohou vám nástroje na vizualizaci otázek. Ty ukazují, jaké otázky si lidé kladou v různých fázích rozhodování.
Dobrým výchozím bodem je Questions report v nástrojích jako Ahrefs. Získáte přehled reálných otázek, které uživatelé zadávají do vyhledávání.
Další možností jsou vizuální nástroje jako AlsoAsked nebo Answer the Public. Ty zobrazují otázky ve formě stromu nebo mapy, takže vidíte, jak na sebe jednotlivé dotazy navazují.
Našeptávače AI
Dalším dobrým zdrojem jsou samotné AI nástroje a jejich našeptávače. Sledujte, jaké návrhy se objevují v rozhraních jako například Perplexity či Grok. Je to rychlý způsob, jak si rozšířit základní sadu promptů ještě před samotnou simulací.
Interní data firmy
Nezapomínejte ani na vlastní interní zdroje. Velmi hodnotné vstupy často najdete tam, kde se zákazníci ptají přímo vás.
Pomáhají zejména:
otázky ze zákaznické podpory,
přepisy chatů,
obchodní hovory,
FAQ z e-mailů,
poznámky od sales týmu.
Tyto zdroje mají jednu velkou výhodu. Zachycují přesně ty otázky, které jsou pro váš byznys reálně důležité. Nejsou to jen obecné dotazy z trhu, ale konkrétní potřeby vašich zákazníků.
Fóra a komunity
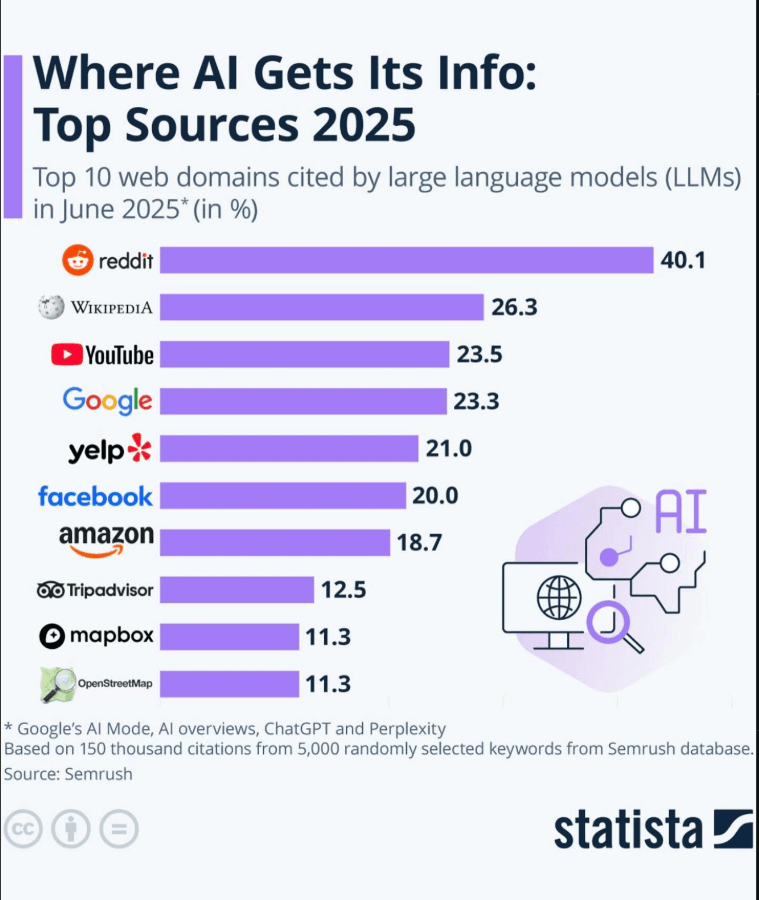
Velmi cenným zdrojem jsou fóra a online komunity, zejména Reddit. Právě tam lidé používají přirozený jazyk, popisují své problémy vlastními slovy a kladou otázky tak, jak je reálně formulují.
To je důležité především proto, že AI systémy často pracují právě s tímto typem konverzačního jazyka. Na fórech najdete:
reálné bolesti uživatelů
časté obavy před nákupem
porovnání alternativ
důvěrové otázky
formulace, které byste sami nevymysleli
Fóra jsou navíc důležitá i z reputačního pohledu. Při více typech dotazů AI chodí na komunitní zdroje ověřovat důvěru, zkušenosti a recenze. Proto mají tato místa význam nejen jako inspirace pro vstupy, ale i jako signál, co AI u daného tématu považuje za důležité.
Je ale třeba dodat i jednu praktickou věc. Reddit v CZ a SK prostředí není u mnoha témat tak silný jako v zahraničí. Pokud proto pro své téma nenajdete dostatek lokálních diskusí, klidně se inspirujte i zahraničním Redditem. Často vám velmi dobře ukáže, jaké otázky, obavy a porovnání lidé u daného tématu řeší.
Vstupy máte. Co dál?
Máte-li zvládnuté vstupy, máte vyhráno víc než polovinu. V této fázi už nejde o to vymýšlet další prompty, ale vzít ty správné, nasimulovat je a pochopit, jaké poddotazy z nich AI reálně generuje.
Skutečná hodnota ale vzniká až v dalším kroku. V tom, jak tato data přetavíte do obsahu. Jak z nich vytvořit strukturu článků, jaké sekce doplnit, jaké otázky pokrýt a kde vám dnes obsah chybí. To ale třeba příště.
Připravte web na éru AI vyhledávání
Uděláme pro vás AI SEO Readiness Audit – konkrétní analýzu toho, kde váš obsah ztrácí a jak ho dostat do odpovědí AI nástrojů.