

















Proč se naučit regulární výrazy? Nekonečné množství dat a někdy repetitivní činnosti jsou denním chlebem SEO specialisty. Regulární výrazy nabízejí efektivní zjednodušení práce a ušetření cenného času.
Regulární výrazy neboli regex umožnují efektivně vyhledávat v textu pomocí speciálních znaků. Tyto specifické znaky (žolíky, v angličtině wildcards) nahradí libovolný počet znaků v textu a vyhledají nebo nahradí tak všechny možné požadované varianty.
Regex vám pomohou odlišit brandové výrazy od non-brandových. Vyhledáte data o výkonu pouze k vybraným klíčovým slovům. Naleznete díky nim konkrétní klíčová slova nebo jejich varianty na svém webu. A pokud nemáte zrovna ideální strukturu webu, umožní vám sledovat návštěvnost a ostatní metriky pouze pro vámi vytvořený segment. Když to zjednodušíme, regulární výrazy vám ušetří čas a pomohou vám dostat se k datům, které byste jinak těžce třídili např. v Excelu.
Tečka – (.) – nahrazuje znak za libovolný neznámý znak.
Svislá čára – (x|y) – je znakem pro význam „nebo“. V tomto případě by se ukázaly všechny možnosti x nebo y.
Interval – ({n, k}) – odpovídá n až k opakování předchozího znaku, pokud je k vynecháno {n, } odpovídá to nejméně n opakování. Pokud interval napíšeme ve tvaru {n}, odpovídá to přesně n opakování předchozího znaku. Příkladem může být výraz Ho{2,6}lka – tento výraz vyfiltruje verze slova Holka obsahující přesně 2 až 6 „o“ – Hoolka, Hooolka, Hoooolka atd.
Hvězdička – (*) – představuje libovolný počet opakování předchozího znaku (0, ∞) Například při zadání výrazu eVisio*ns bude výsledkem „eVisins“, „eVisions“ i „eVisiooooons“.
Kulaté závorky – () – skupina znaků.
Plus – (+) – představuje jeden nebo více výskytů předchozího znaku (1,∞), pokud tedy chceme najít všechny varianty slova eVisions, které obsahují alespoň jedno „o“, napsali bychom následovně „eVisio+ns“ – výsledkem by bylo „eVisions“, „eVisioons“ i „eVisioooooons“.
Otazník – (?) – představuje žádný nebo právě jeden výskyt předchozího znaku (0,1) – evisio?ns = evisins, evisions.
Zpětné lomítko – (\) – ruší význam znaku, kterému zpětné lomítko předchází, což umožňuje vyhledávat interpunkční znaménka.
Hranaté závorky – ([]) – vyfiltrují všechny možnosti znaků vepsané do těchto závorek. Výraz je vhodný při vyhledávání gramatických chyb v textu – své[szš]t = svést, svézt, svéšt. Můžeme použít spojovník (-) jako operátor rozsahu. Pokud v hranatých závorkách použijeme znak stříška ^, jde o negovaný seznam a představuje všechny libovolné znaky vyjma těch, které do hranaté závorky napíšeme.
TIP: Správnou kombinací znaků se dá najít velké množství vyhledávacích vzorů. Například kombinací tečky a hvězdičky můžeme najít všechna slova obsahující určitá písmena v libovolném pořadí. Např. „.*o.*a“ vyfiltruje všechna slova, která mají někde na začátku písmeno „o“ a někde později písmeno „a“.
Pro vyzkoušení a naučení regulárních výrazů je vhodný regex tester – https://regex101.com/
Rozsáhlejší seznam regulárních výrazů naleznete – ZDE
Pojďme se nyní podívat, jak SEO konzultant může pomocí nástrojů, které denně používá, regulární výrazy využít. Je důležité svá data segmentovat, a pokud má váš klient více než 1000 URLs, je téměř nemožné data analyzovat ručně. Detailnější pohled vám pomůže nalézt vyhledávací vzory, příležitosti pro optimalizaci a obecně budete mít větší přehled o svém projektu. Regulární výrazy můžeme využívat v nejdůležitějších nástrojích SEO specialisty. Od Google Analytics přes Screaming Frog až po OpenRefine. Můžeme si tak jednoduše segmentovat data dle potřeb. Filtrovat brandovou vs. non-brandovou návštěvnost, segmentovat web podle vstupních stránek a v neposlední řadě můžeme regex využít k analýze klíčových slov v OpenRefine.
Nejjednodušším příkladem, jak začít s regulárními výrazy, je zjištění podílu brandových a non-brandových výrazů. Velmi často se setkáváme s tím, že jsou brandové výrazy různě variovány a lidská představivost někdy snese opravdu vše. Zejména pak u cizojazyčných brandů. V takových případech je někdy na první dobrou opravdu složité si všechny variace odfiltrovat a dojít ke konkrétním datům. Na příkladech níže si ukážeme možnosti, jak regulární výrazy využít.
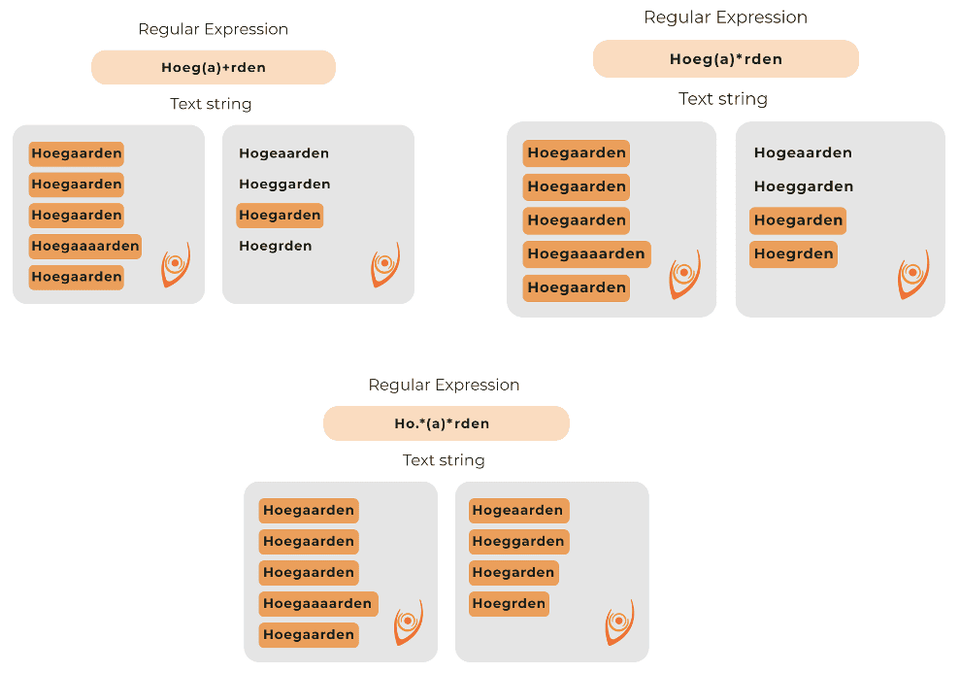
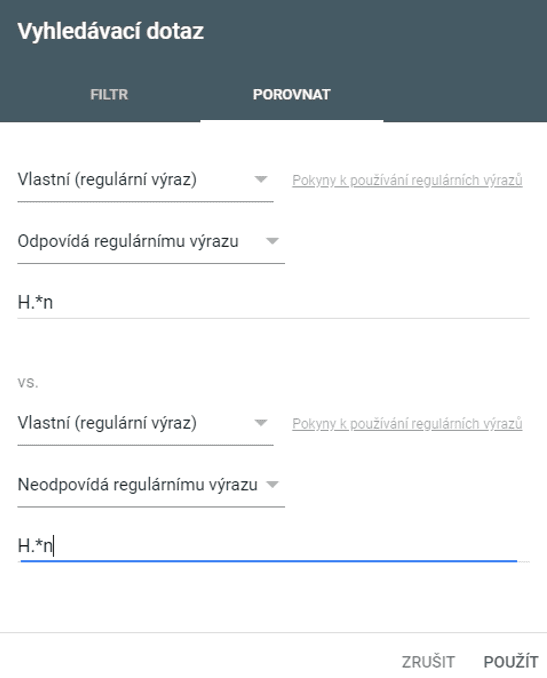
Na příkladu níže vidíme 3 různě napsané regulární výrazy v názvu Hoegaarden. Hoeg(a)+rden ukáže všechny možnosti, kde se v názvu objeví jedno nebo více „a“. To však neukáže názvy, kde uživatel nenapsal žádné „a“.
K tomu nám pomůže (*), která představuje libovolný počet znaků napsaných před ní. Nejlepším výrazem pak je H.*n, který předpokládá, že uživatel zná první a poslední písmeno, avšak neví, v jakém pořadí a počtu jsou znaky uprostřed slova.
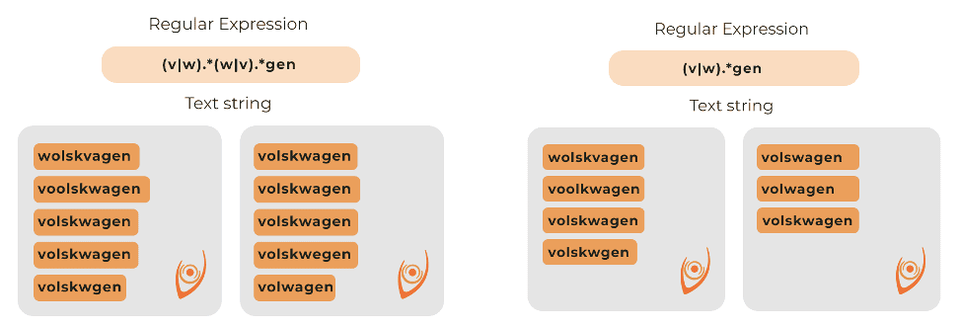
Dalším příkladem je značka Volkswagen. Na příkladu výše vidíme dva různé způsoby, jak najít špatně napsaný brand. U druhého příkladu, kdy napíšeme (v|w).*gen, odchytíme více chybně napsaných názvů, pakliže předpokládáme, že uživatel napíše na začátku slova „v“ nebo „w“, pak libovolné znaky uprostřed a na konci napíše „gen“.
Regulární výrazy zde mohou být využity k segmentaci nejdůležitějších stránek, jako jsou produktové stránky, kategorie, blog atd. V ideálním případě má váš web logickou strukturu ve formátu example.cz/kategorie/… V případě, že to tak není, je zapotřebí vytvořit skupinu určitého vzorku URL do jednoho segmentu. Díky tomu, že si vytvoříte vlastní unikátní segment, se pak dostanete ke konkrétním metrikám, jako je např. bounce rate nebo konverzní poměr jen k tomuto danému segmentu. Jak k tomu přistupovat?
Pozor – U GA se regulární výrazy dají využít pouze u landing page, ne u klíčových slov.
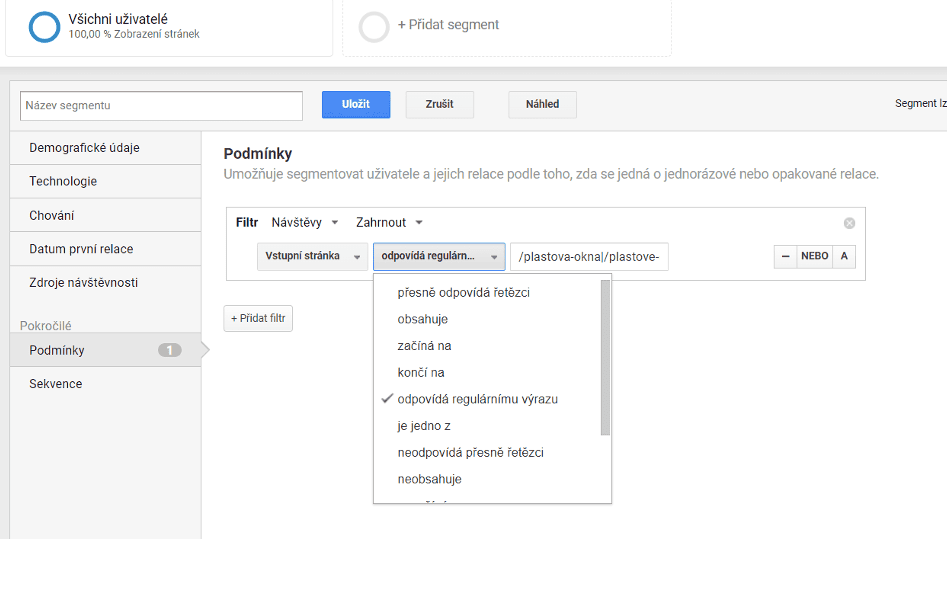
Na obrázku výše vidíme, jak v Google Analytics můžeme segmentovat data podle produktů (vstupních stránek) a efektivně tak analyzovat data dle potřeby. Můžeme zde pomocí operátoru „|“ (nebo) vypsat hlavní nabízené produkty vašeho webu a porovnávat tak jejich výkon. Příkladem tohoto regulárního výrazu je „example.cz/plastova-okna/|/plastove-dvere/|/hlinikove-dvere/“, kdy filtrujeme zmíněné vstupní stránky.
GSC vám poskytne data o tom, jaký je výkon vašich stránek ve výsledcích vyhledávání. Pokud např. zrovna rozšiřujete určitou kategorii na svém webu a chcete se v čase podívat na výkon konkrétních klíčových slov, tak vám opět pomohou regulární výrazy. V GSC můžeme regulární výrazy používat jak na vstupní stránky, tak na dotazy. Můžeme segmentovat důležité stránky, produkty, kategorie, blog apod. a dostat se k metrikám jako kliky, imprese, míra prokliku nebo průměrná pozice pro specifické datasety.
Jak k tomu přistupovat?
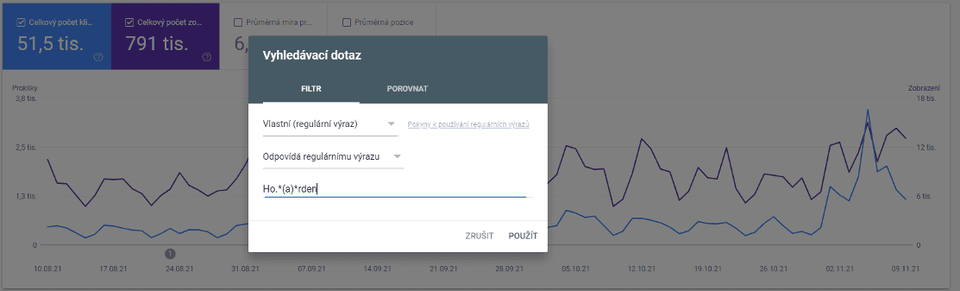
Můžeme je využít například k vyfiltrování brandové návštěvnosti.
V Google Search Console si můžeme vyfiltrovat pouze dotazy, které chceme (konkrétní datové sady), výkon této konkrétní datové sady (kliknutí, zobrazení, CTR, viditelnost), výkon konkrétních dotazů z této datové sady, výkon zařízení a rozdělení URL adres.
Dalším skvělým využitím regexu v GSC je filtrace brandové vs. non-brandové návštěvnosti. Při vyfiltrování tak vidíme poměr a vývoj této návštěvnosti.
Základem pochopení každého SEO projektu je analýza klíčových slov. Poskytne ucelenou představu o tom, která klíčová slova a fráze jsou relevantní pro váš web. V OpenRefine pomocí regexu hromadně rozřadíme klíčová slova do daných segmentů, například při různém skloňování, gramatických chybách a při hledání určitých vzorů vyhledávání. Můžeme zde použít například operátor rozsahu [0-9][10-19], vyfiltrovat si tak čísla od 0 do 19. To může být vhodné při filtraci klíčových slov dle roku výroby nebo podle sériového čísla a podobně. Dále můžeme využít operátor „nebo“ sv(é|e)(z|s)t při hledání gramatických chyb. V tomto případě by se nám vyfiltrovala všechna slova – svézt, svezt, svést, svest…
Příkladů by mohlo být mnoho, je jen na vás, jakým způsobem k filtraci přistoupíte.
Dalším skvělým příkladem využití regexu v OpenRefine je filtrace spamových domén.
V případě, že vaši doménu napadnou spamové odkazy, trvá někdy až hodiny si tyto domény ručně vyfiltrovat. Tato metoda ušetří až 2 hodiny času.
Jak postupovat?
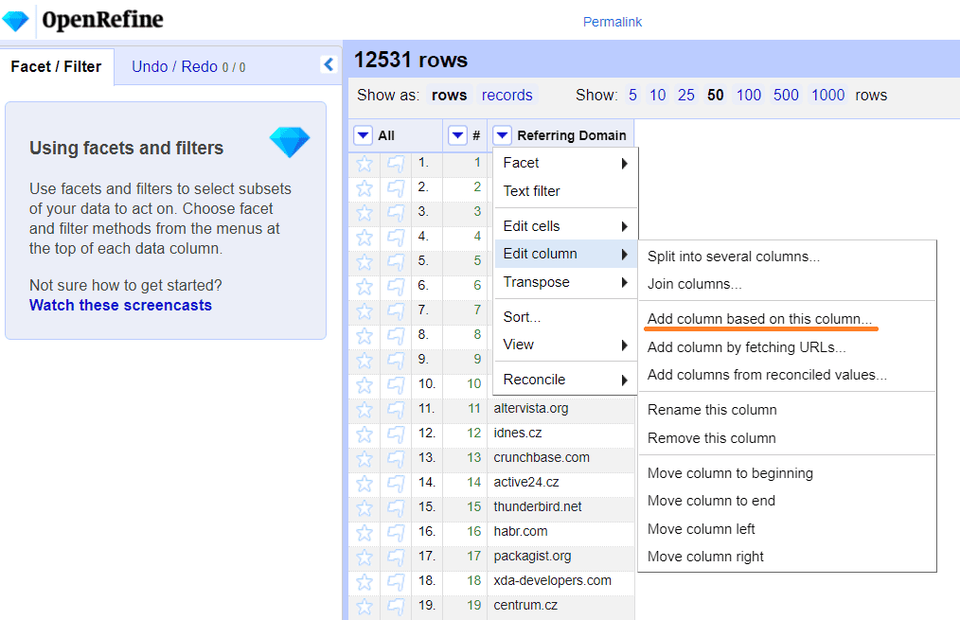
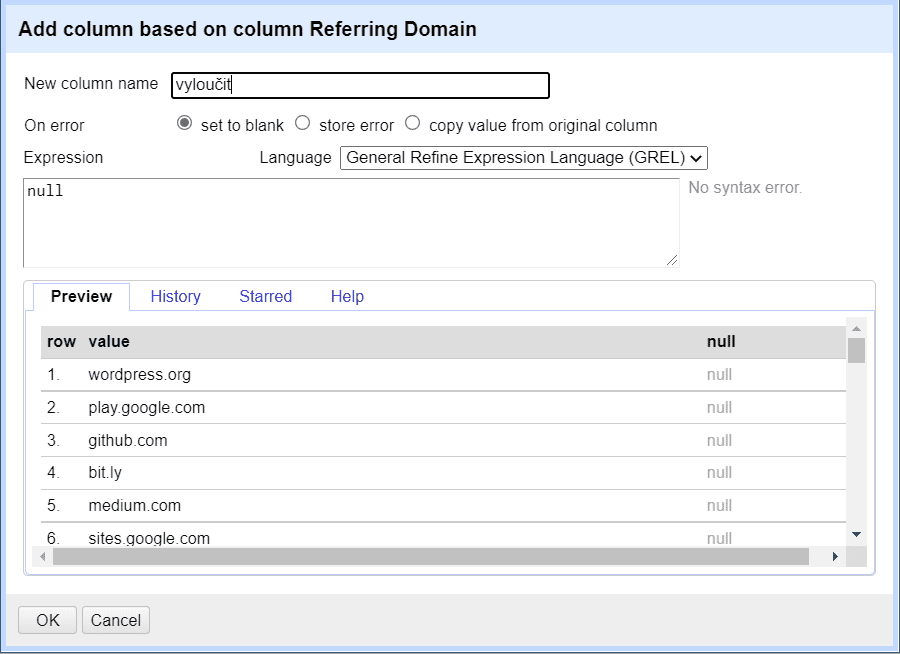
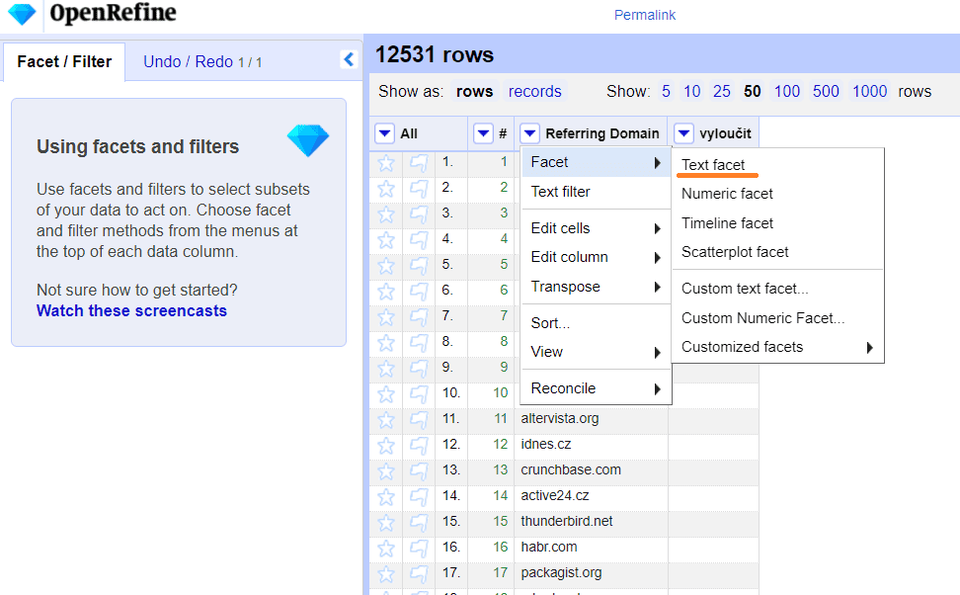
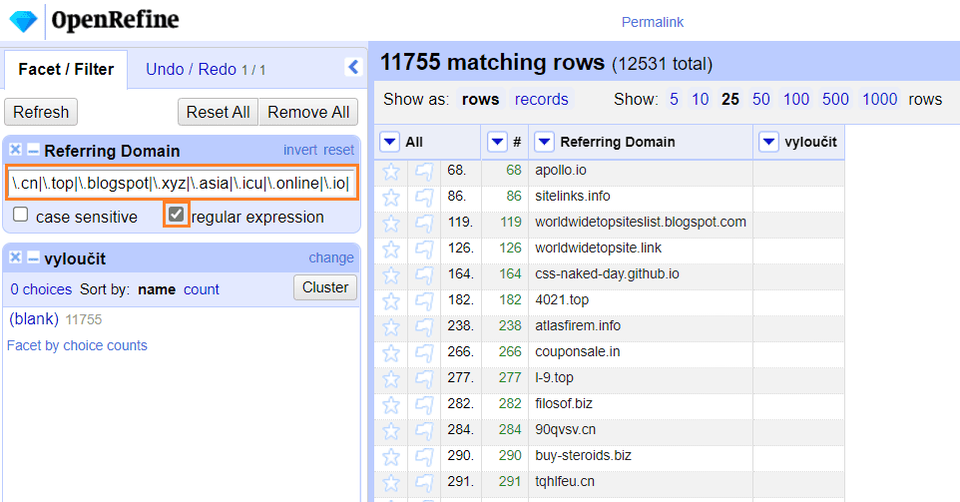
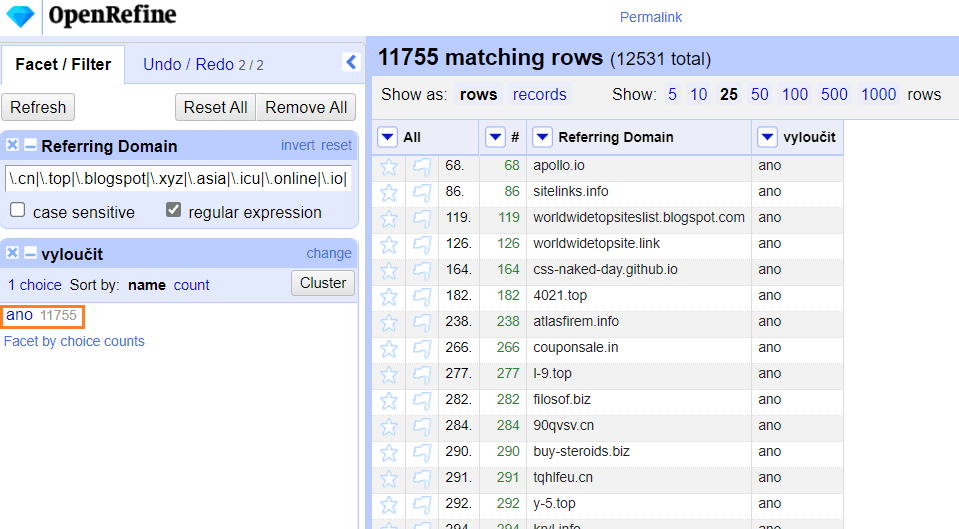
Nezapomeňte si výsledný seznam k distancování ještě ručně projít. Některé domény vypadají na první pohled pochybně, ale po důkladném zkontrolování můžeme narazit na hodnotné odkazy. (Jedná se především o domény s koncovkou .info, .biz, .blogspot.com.)
V tomto nástroji můžeme regulární výrazy využít hned k několika činnostem, jako je např.:
Jedním z příkladů může být hledání interních odkazových příležitostí na webu. Nejjednodušší cestou je vytvořit regulární výraz klíčových slov, které na webu chcete nalézt, a pomocí custom search vyhledat konkrétní fráze.
Na první pohled se zdá, že naučit se regulární výrazy je složité, ale jakmile objevíte jejich sílu a vyzkoušíte si je v praxi, zjistíte, že se bez nich nemůžete obejít.

